
Unexpected Target Imbalance: What to do?
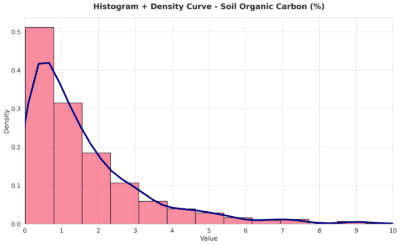
In NIR analysis, we have found spectral outliers, which we have removed using exploratory methods. However, we have also faced another challenge in this dataset: a severe imbalance in the target variable. Many more samples were taken at low target values, while very few samples corresponded to higher values.
In theory, it is recommended to have samples perfectly distributed across the target values. However, obtaining such a distribution in practice is often difficult or impossible. In real-world situations, some target values naturally occur more frequently than others. Is it still worthwhile to include the few samples at the extremes? We think so, because they contribute to the robustness of the model.
So how do we “solve” the problem of an imbalanced target? Considering extreme target values as outliers might be tempting, but this is incorrect. We must remember the definition of an outlier: an error, mislabeling, or observation that does not follow the general trend, an aberrant sample. Extreme values in the target are not outliers; they follow the underlying X–Y relationship. Their sparsity does not justify removing them. We are talking about Y values, not X values.
There are several strategies to address this situation. One approach is to assign different weights to the samples: higher relative weight for the extremes and lower weight for samples in densely populated regions. Another strategy is to stratify the models, creating separate models for different ranges of the dependent variable.
In such cases, using R² as your guide is not advisable, because it reflects the explained variance relative to total variance. At the extremes, explained variance will naturally be lower than in regions surrounded by many neighbors. Therefore, metrics like RMSEP are more appropriate in these situations.
Another strategy to mitigate target imbalance is to transform the target variable. Applying transformations help reduce skewness and compress the range of extreme values. This improves model stability, facilitates learning across the entire range of the target, and prevents the model from being overly biased toward the densely populated regions.
Dataset: https://lnkd.in/eX68uCWz